attention is all you need(Vaswani,2017)에서 나오는 가장 기본적인 standard transformer에서 제안한 attention score는 아래와 같다.
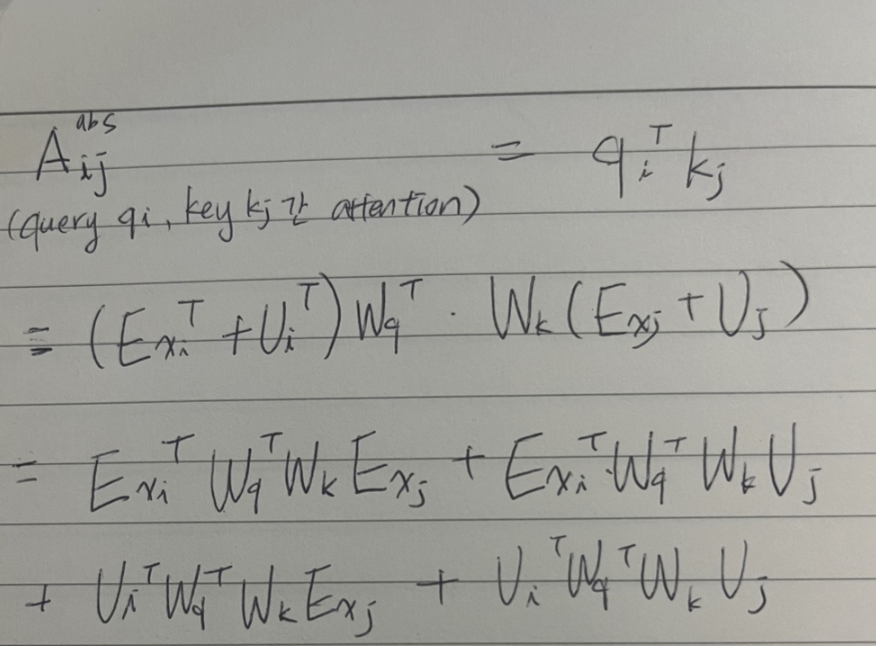
여기서 query와 key앞에 positional embedding 정보를 담는 U는 모델에 따라서 sinusoid (sin, cos등을 통해 non trainable한 형태로 고정) 혹은 trainable parameter가 될 수 있음.
위의 식에서 Ex, U는 논문에 따라서 X, p등으로 표시되기도 함
위의 standard transformer의 attention을 decompose한 마지막의 4가지 term중에서 일부 텀을 대체하거나 없애는 식으로 positional embedding의 방법론이 발전함.
RoFormer논문에서 equation 7인 아래의 식을 보면, key의 positional embedding값인 Uj가 relative positional embedding parameter인 Uj-i로 대체되고, query의 positional embedding값인 Ui는 각각 3,4번째 term에서 u,v의 trainable parameter로 대체 되었음을 알 수 있음.
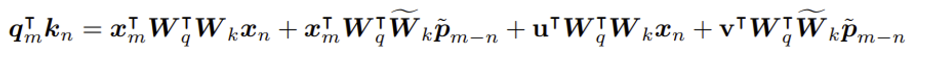
RoFormer논문에서 equation 8로 소개된 아래의 식을 보면 역시 standard식에서 변형한 것으로, 첫번째 term만 남기고 2,3,4번째 term은 모두 삭제 후, positional embedding값은 bij인 trainale parameter로 나타냈음을 확인 할 수 있다.
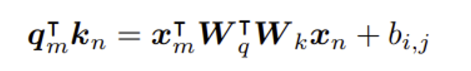
이와 같이 key와 query는 각각 non positional한 mapping을 담당하는 E(아래식에서는 Xi), positional한 정보를 담는 U(아래식에서는 Pi)로 구성되는데, RoFormer에서 언급하는 이전 연구들에서 U는 additive한 형태로 +로 연결되어 bias와 같이 대부분 나타내었다.
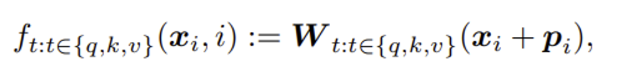
RoFormer에서 제안하는 positional embedding은 이러한 U를 additive가 아닌 multiplicative하게 변경하는 것이다.
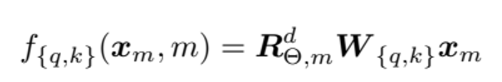
위의 +p_i부분이 아래의 RoFormer에서는 R로 시작하는 relative positional information을 담은 orthogonal rotary matirix로 나타나게 된다.
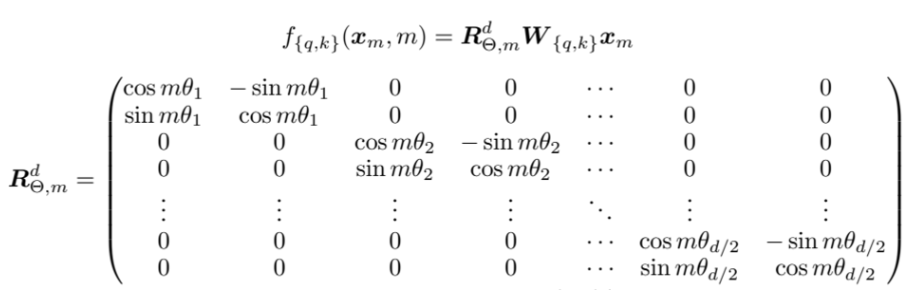
위의 matrix는 2차원 회전변환 matrix인 아래의 식을, 표현하려는 embedding vector의 dimension의 2로 나눈만큼 펼쳐 표현한것임.
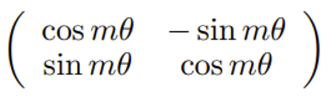
(참고) rotary matrix를 e^ix등의 형태로 나타내는 이유는 오일러 공식과 관련해서인데 이해에 도움이 갈 만한 사이트를 첨부함. https://satlab.tistory.com/91
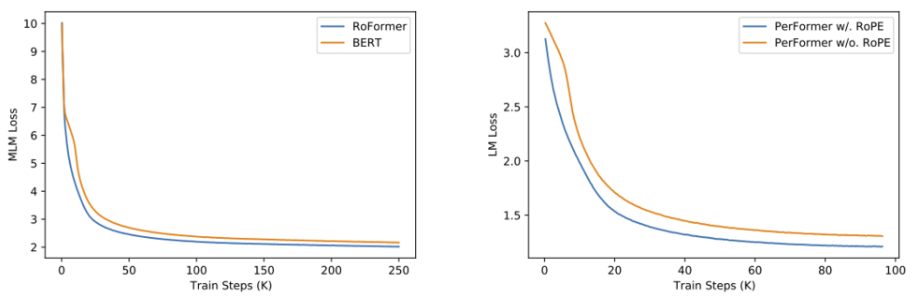
이러한 RoPE를 도입하여 실험을 해 본 결과, RoFormer는 standard transformer model보다 더 나은 BLEU score를 기록했다고 하며, MLM loss도 더 낮게 빠르게 수렴하였다고 한다.
'논문읽기' 카테고리의 다른 글
| 논문_REACT (Reasoning and Acting) (0) | 2023.11.27 |
|---|---|
| 논문 초록읽기 (딥러닝,LLM관련) (0) | 2023.11.26 |
| LoRA(LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGEMODELS ) 논문읽기 (4) | 2023.11.25 |
| [딥러닝 논문읽기] Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing (얼굴위조방지 관련 모델) (0) | 2023.01.05 |



