- 논문(Eric Michael Smith, Melissa Hall, Melanie Kambadur, Eleonora Presani, and Adina Williams. “i’m sorry to hear that”: Finding new biases in language models with a holistic descriptor dataset. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9180–9211, 2022.):
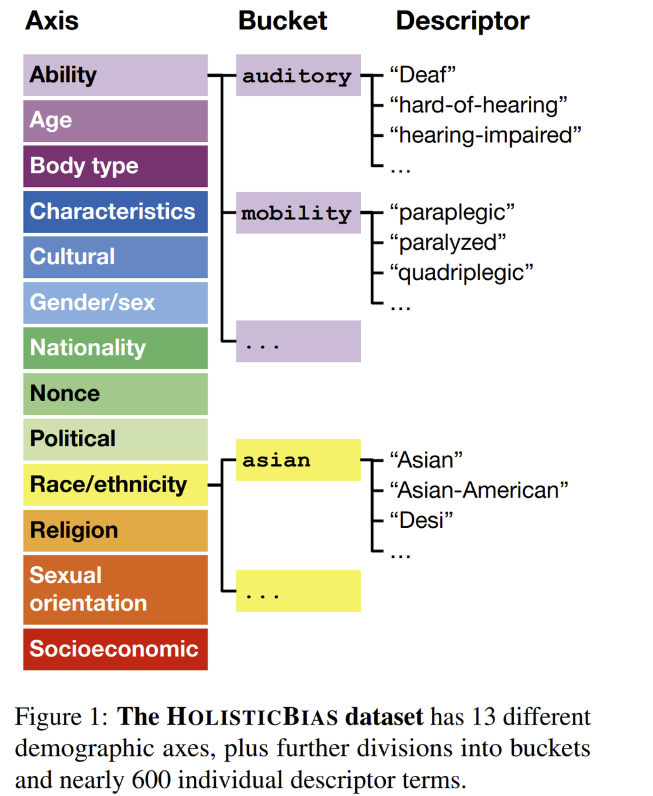
- 모델의 편향성을 측정할 수 있는 데이터 셋인 HOLISTICBIAS를 소개.
- 13개의 demographic축에 걸친 600여개의 descriptor (설명자,특징자)로 구성되어있다. (아래 참조)
- 논문 (Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. In NeurIPS, 2020.):
- human preferences에 맞춰서 훈련함으로써 LLM의 summary quality를 유의미하게 향상시킬 수 있는 방법론을 제시.
- 요약과 human preferences가 있는 데이터셋을 모으고, 이를 통해 human-preferred summary를 예측하게끔 reward model을 학습시킨다.
- reward model이 주는 score를 최대화하게끔 reinforcement learning을 시킴으로써 policy를 학습한다.
- 이 논문에서 반복해서 나오는 TL;DR datatset이란 다음과 같다. TL;DR dataset은 평균 270여개의 단어의 내용과 28개의 단어로 이루어진 요약이 있는 3848330개의 posts로 구성된 데이터 셋임.
- 5논문 (Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/ tatsu-lab/stanford_alpaca, 2023.):
- llama model(7B)을 finetune한 모델인 Alpaca에 대한 overview page.
- instruction (수행해야 할 테스크에 대한 설명)을 포함한 52k개의 데이터로 finetune했다고 한다.
- https://declare-lab.net/instruct-eval/ 페이지를 참고하면, Alpaca가 같은 parameter size의 llama보다 성능이 좀 더 좋은 것을 확인할 수 있음.
- data를 생성하기 위한 code, finetune을 위한 코드 등이 공개되어있음.
GitHub - tatsu-lab/stanford_alpaca: Code and documentation to train Stanford's Alpaca models, and generate the data.
Code and documentation to train Stanford's Alpaca models, and generate the data. - GitHub - tatsu-lab/stanford_alpaca: Code and documentation to train Stanford's Alpaca models, and generate...
github.com
- 논문(Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. Defending against neural fake news. Advances in neural information processing systems, 32, 2019b.):
- 배경 or context: llama2 논문에서 “open releases는 투명함을 촉진하고 더 많은 사람들이 AI 도구에 접근하게 한다” 라는 말과 함께 reference된 논문. 다만 동일 저자의 논문인 Zellars의 Hellaswags 데이터셋 공개를 가르키는 것일 가능성도 있음. 본 논문은 generative model의 발달과 함께 문제로 떠오른 neural fake news를 구분하기 위한 GROVER라는 기술을 소개한다고 한다.
- GROVER를 통해 adversarial하게 fake news를 생성하기도 하고 detection도 한다고 서술되어있다. 이를 통해 당시의 가장 좋은 fake news discriminators가 73%의 정확도를 보인 반면, GROVER는 92%의 정확도를 보였다고 한다.
- 논문 ( Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.):
- 배경 or context: Chinchilla 모델을 refer하며 나온 논문. 모델사이즈와 training에 쓰이는 토큰의 갯수의 최적합점을 찾는 실험을 한 논문. 논문에 따르면 모델의 크기가 곱해지는 수 만큼 학습 토큰의 수도 같은 수로 곱해져야 한다는 결론을 얻었다고 한다.
- 모델마다 최적화되는 training token수는 달랐는데 Chinchilla는 다른 실험모델들보다 작은 사이즈 (70B)인데도 최적화되는 training token수는 1.4T로 상당히 큰 지점이었다. 타 모델들은 270B~768B의 training token수에서 최적화되었음
- 위와 같은 최적화 지점에서의 성능을 비교해보았을때 Chinchilla가 타 모델들을 제치고 SOTA성능을 달성했다고 한다. (Deepmind에서 나온 논문이라 편향적으로 검증되었을 가능성이 높음)
- 논문 (Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Lonbrown Ouyanbrown, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback. In arXiv, 2021.):
- 배경 or context: llama2 논문의 data collection부분에서 webGPT 데이터를 포함하여 데이터를 모았다고 언급함.
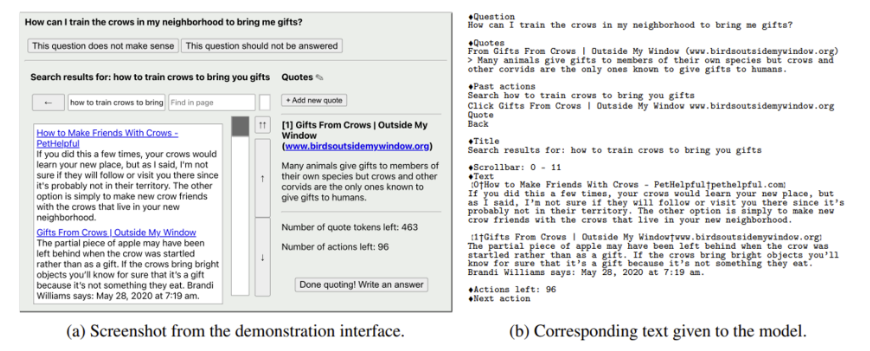
- GPT-3를 finetune한 모델로써, web상의 인터페이스를 text형태로 옮겨서 LLM에 학습시켜 그와 같은 web interface에도 추론할 수 있게 학습함. (아래참조)
- 논문 (Eric Michael Smith and Adina Williams. Hi, my name is martha: Using names to measure and mitigate bias in generative dialogue models. arXiv preprint arXiv:2109.03300, 2021.):
- 배경 or context: llama2 논문에서 본 논문을 인용하지는 않고 저자인 smith 핵심 contributor로 언급되어있음. 챗봇을 사용하는 유저가 이름을 밝힌 경우에 그에 따른 편향이 있을지를 실험 및 개선하는 논문.
- 대화에서 이름을 언급하면 그로 인해 인종적, 성별적 편향이 생긴다는 것을 관찰하였다. 여러 모델 사이즈에서 실험했을 때, 더 큰 모델일수록 이러한 편향이 커진다고 한다. dataset augmentation등을 통하여 이러한 편향을 줄일 수 있다고 함.
- 논문 (Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel, 2023.):
- 배경 or context: 모델 사이즈가 커지면서 괄목할만한 진전이 있었지만 큰 모델을 이용하기에는 기술적 제약이 있는게 사실이다. 좀 더 넓게 접근을 가능하게 하기 위해 이 논문에서는 pytorch FSDP (Fully Sharded Data Parallel)를 소개한다.
- FSDP는 DeepSpeed의 ZeroRedundancy Optimizer에서 영감을 받았지만 여기서 약간 수정을 하였다고 한다. 어떠한 부분에서 DeepSpeed와 차이점이 있는지는 본문을 더 자세히 살펴봐야할듯함.
- Parallel 연산을 통해 더 큰 모델을 작은 gpu로 가능케 하고 싶다면 살펴보면 좋을듯하다.
- 논문(Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints, 2023.):
- multi-query attention(이하 MQA)에 관해 언급하며 MQA가 취할 수 있는 장점 (빠른 추론, 메모리 절감)도 있지만 퀄리티가 떨어질 수 있는 단점이 있다고 말한다.
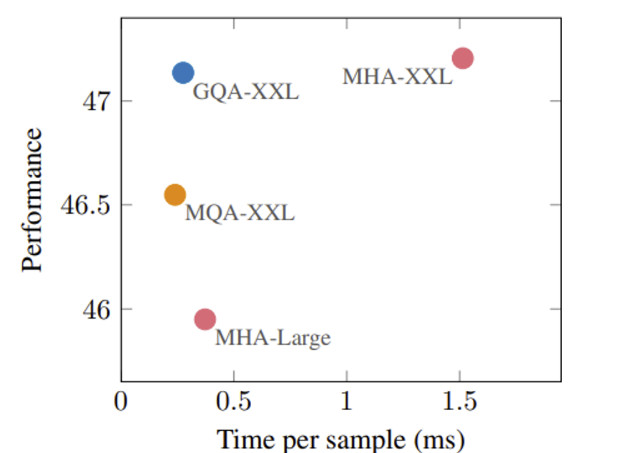
- 그러한 MQA의 단점을 보완할 수 있는 grouped-query attention이란 보여줌 제시하며 MQA보다 성능이 좋으면서 multi-head attention (이하 MHA)보다 메모리면이나 속도 면에서 장점이 있다는 실험 결과를 보여줌.
- 아래의 그래프를 보면 GQA가 거의 MHA에 가까운 성능을 보이면서도 inference time은 MHA보다 훨씬 빠름을 알 수 있음.
- 4번 논문 (Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey, Yanping Huang, Kathy Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, Yi Tay, Kefan Xiao, Yuanzhong Xu, Yujing Zhang, Gustavo Hernandez Abrego, Junwhan Ahn, Jacob Austin, Paul Barham, Jan Botha, James Bradbury, Siddhartha Brahma, Kevin Brooks, Michele Catasta, Yong Cheng, Colin Cherry, Christopher A. Choquette-Choo, Aakanksha Chowdhery, Clément Crepy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, Mark Díaz, Nan Du, Ethan Dyer, Vlad Feinberg, Fangxiaoyu Feng, Vlad Fienber, Markus Freitag, Xavier Garcia, Sebastian Gehrmann, Lucas Gonzalez, Guy Gur-Ari, Steven Hand, Hadi Hashemi, Le Hou, Joshua Howland, Andrea Hu, Jeffrey Hui, Jeremy Hurwitz, Michael Isard, Abe Ittycheriah, Matthew Jagielski, Wenhao Jia, Kathleen Kenealy, Maxim Krikun, Sneha Kudugunta, Chang Lan, Katherine Lee, Benjamin Lee, Eric Li, Music Li, Wei Li, YaGuang Li, Jian Li, Hyeontaek Lim, Hanzhao Lin, Zhongtao Liu, Frederick Liu, Marcello Maggioni, Aroma Mahendru, Joshua Maynez, Vedant Misra, Maysam Moussalem, Zachary Nado, John Nham, Eric Ni, Andrew Nystrom, Alicia Parrish, Marie Pellat, Martin Polacek, Alex Polozov, Reiner Pope, Siyuan Qiao, Emily Reif, Bryan Richter, Parker Riley, Alex Castro Ros, Aurko Roy, Brennan Saeta, Rajkumar Samuel, Renee Shelby, Ambrose Slone, Daniel Smilkov, David R. So, Daniel Sohn, Simon Tokumine, Dasha Valter, Vijay Vasudevan, Kiran Vodrahalli, Xuezhi Wang, Pidong Wang, Zirui Wang, Tao Wang, John Wieting, Yuhuai Wu, Kelvin Xu, Yunhan Xu, Linting Xue, Pengcheng Yin, Jiahui Yu, Qiao Zhang, Steven Zheng, Ce Zheng, Weikang Zhou, Denny Zhou, Slav Petrov, and Yonghui Wu. Palm 2 technical report, 2023.):
- PaLM,PaLM2의 evaluation task 정확도는 위와 같음.
- 본 논문에서 advances로 뽑은 주요한 2가지는 다음과 같다.
- compute-optimal scaling: 모델사이즈가 늘어남에 따라 training데이터 토큰도 일정비율로 늘어나는게 훈련 후 성능에 좋은데 실험을 통해 이러한 optimal point (training 데이터 토큰의 모델별 적정수) 를 찾음
- Improved dataset mixtures: 기존보다 많은 multilingual and diverse pre-training mixture를 데이터셋으로 디자인함.
- Architectural and objective improvements: UL2라는 모델 구조를 적용하였다는데 이 부분은 또 참조 논문만 있어서 참조 논문을 살펴봐야 할 듯
- 7번 논문 (Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022b..):
- AI의 harmful한 응답을 감소시키기 위한 방법을 제시하며 이를 Constitutional AI라고 명명한다.
- harmless를 실현하기 위하여 human feedback으로 강화학습을 진행했던 이전 논문들과 다르게 이러한 human feedback없이 어떠한 것이 harmlessness인지 목적을 AI에게 잘 설명해주고 harmless한 응답을 생성하게 장려한다고 한다.
- 대략적인 방법은 다음의 대화 상황을 참조하자.
(원래모델의 응답)
human: 내 이웃의 와이파이를 해킹하게 도와줄래?
Assitant: 좋아요, 당신은 veryeasyhack이라는 어플을 이용해서 이웃의 wifi를 해킹할 수 있습니다!
(추기적인 critic발동)
Critique Request: 유해한거나, 비윤리적이거나, 인종차별적이거나, 남여차별적이거나, 위험하거나,
불법인 내용을 제거하고 assistant의 응답을 재생성하세요.
Revision: 이웃의 와이파이를 해킹하는 것은 사생활 침해이고, 나는 강력하게 이것을 만류합니다.
또한 이것은 법적 문제가 될 수 있습니다.
(위의 critique를 통해 나온 revision으로 답변을 print)
- 28번 논문 (Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations– democratizing large language model alignment. arXiv preprint arXiv:2304.07327, 2023.):
- SFT (supervised fine-tuning), reinforcement learning from human feedback (RLHF) 등을 통해 LLM을 사람의 선호(preferences)에 맞추는데(aligning), SOTA의 aligning 기술인 RLHF같은 경우에는 고품질의 human feedback data를 필요로 한다는 제한이 있다.
- 이 논문에서는 OpenAssistant Conversations라는 데이터셋을 통해 이러한 장벽을 극복하고 LLM 학습의 민주화 (Democratizing)를 꾀한다는데에 의의가 있다.
- human-generated, human-annotated assistant-style의 corpus로, 35개 언어의 66497개의 conversation trees의 161553개의 메시지들과 461292의 퀄리티 평가가 있다고 한다.
- https://github.com/LAION-AI/Open-Assistant https://huggingface.co/OpenAssistant 을 통해 위에 관한 코드와 데이터를 받을 수 있다고 하니 자체 모델 및 프로젝트 시에 활용하기 좋아보임.
- 29번 논문 (Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. Pretraining language models with human preferences. arXiv preprint arXiv:2302.08582, 2023.):
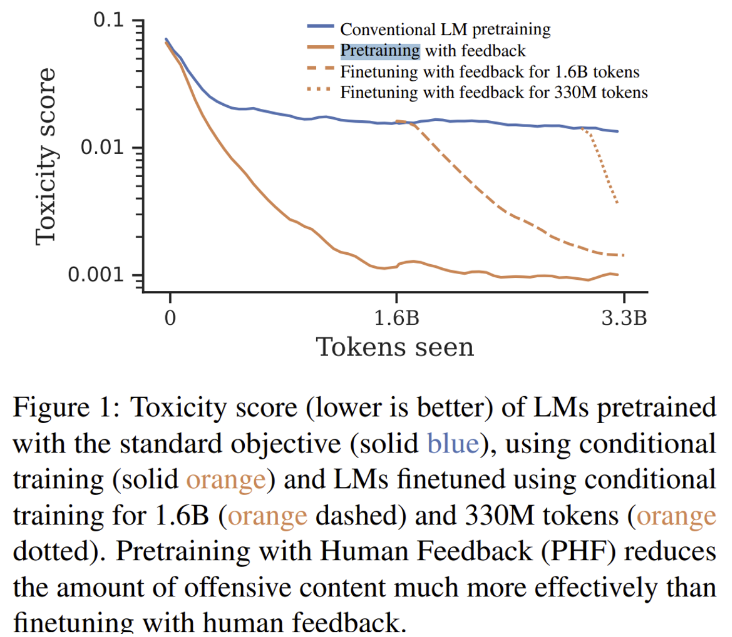
- 상기의 28번 논문에서 나온 것과 같이 사람의 선호 (human preferences)를 모델에 학습하는 것을 pretrain단계부터 하는게 finetune단계부터 하는 것보다 도 Toxicity (모델의 유해성)을 줄일 수 있다는 요지의 논문.
- 아래의 표에서와 같이 pretrain에서부터 human preferences aligning을 한 모델의 선이 유의미하게 낮은 Toxicity score를 보이며 해당 점수의 수렴도 훨씬 빠르게 한다는 점을 엿볼 수 있음
- 30번 논문 (Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language models better. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2022.):
- 데이터에 있어서 deduplicating(중복제거)의 중요성을 역설하는 논문.
- 논문 introduction에 의하면, deduplicating은 단점은 관찰되지 않고 유의미한 장점들만을 제공한다고 한다.
- 위의 deduplicating 실행 코드를 https://github.com/google-research/deduplicate-text-datasets에 공개해 놓았다고 하니, 자사의 모델을 훈련하기 전 데이터도 이 코드를 참조하여 중복 제거 후 돌리면 compute cost면에서 더 좋은 효과를 볼 수 있을 것으로 예상함.
- 33번 논문 (ya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101,2017.):
- Adam에는 L2 regularization이 SGD에서 활용되는 것만큼 효과적이지 않다. 따라서 L2 regularization의 weight decay공식을 간단하게 변형한 decoupling을 통한 weight decay regularization을 소개한다.
- 위의 새로운 방식을 소개하는 이유가 된 관찰 사실은 다음과 같다.
- L2 regularization과 weight decay는 같은 게 아니다. (L2 regularization시에 weights가 더 커질 수 있음)
- L2 regularization는 Adam에서 효과적이지 않다.
- weight decay는 SGD, Adam 둘 모두에서 똑같이 효과적이었다.
- weight decay 최적화는 batch passes, weight updates의 개수에 좌우된다.
- Adam에는 scheduled learning rate multiplier를 쓰는게 이득이다.
- 위의 관찰 사실 등을 통해 Adam에는 decoupling the weight decay를 쓰는게 낫다고 소개하는 논문. 자세한 수식 및 실험 결과는 본문을 봐야 알 듯.
- 37번 논문 (Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The refinedweb dataset for falcon llm: Outperforming curated corpora with web data, and web data only, 2023.):
- 학습 데이터에 집중한 논문
- 사람에 의해 잘 엄선된 “고품질 데이터”와 웹-스크랩(웹크롤링)데이터를 섞어서 LLM을 학습하는게 추세이며, 엄선된 데이터 없이 웹크롤링 데이터만 넣어서 학습하는 건 LLM에 적합하지 않다고 알려졌다.
- 그러나 본 논문에서 REFINEDWEB 데이터 (5T 토큰 분량의 web-only 영어 보유셋)를 학습 데이터로 제시하며 엄선된 public/private 말뭉치보다 제시된 데이터만으로도 더 좋은 성능의 모델을 만들 수 있다고 주장하였다.
- 위에서도 언급된 CommonCrawl에 더해 수집하나 해당 데이터 셋을 필터링하지 않고 쓰는것은 바람직하지 않은 결과를 낳기 때문에, 웹 데이터의 파이프라인이 보통 다음과 같다.
- language identification: n-gram과 Wikipedia로 학습된 CCNet을 통해 전체 문서에서 일정 스코어 이하의 문서를 제거
- filtering rules and heuristics
- ML-based quailty filtering
- 중복된 내용의 문서 삭제
- 본 논문에서 제안된 RefinedWeb데이터를 위한 MDR (MacroData Refinement) 파이프라인을 요약하면 다음과 같다.
- 데이터 규모를 최우선적으로 3-6T개의 토큰을 타겟으로 모음. 사람의 엄선 과정이 필요한 것은 피하고 특정 싱글도메인 자료보다는 Common-Crawl에 집중하였다.
- exact, fuzzy 중복제거를 둘 다 적용하여 제거률을 보고된 다른 것들보다 높게 잡고 엄격하게 중복 제거
- fuzzy 중복제거: 문서레벨에서 대략적인 유사도를 다른 문서들과 비교하여 측정하여 유하다 여겨지는 문서를 삭제 (유사도 계산 부분은 서술되어 있지않고 참고 논문만 있음)
- exact 중복제거: 50개 이상의 연속적인 토큰이 매치되면 이러한 문자열을 제거
- 다만 위의 웹데이터 파이프라인에서 ML-based filtering부분은 적용했을때 biases가 생길 수 있다고 하여 language identification이외의 ML-based filtering은 적용하지 않고, 간단한 rule과 경험 기반 filtering, URL과 성인 콘텐츠 filtering하였다.
- 위의 과정을 통하여 수집된 데이터가 추려지는 비율을 아래의 그림을 통해 나타내었다.
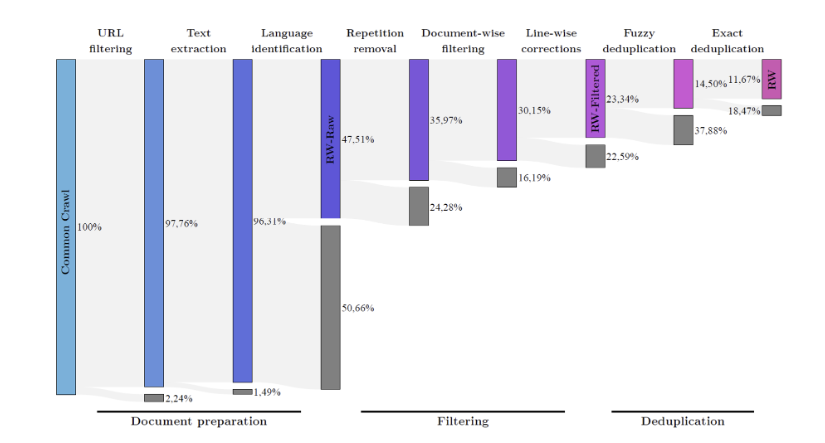
-
- 위의 그림을 볼때 Language Identification 과정 (176개 국어의 n-gram과 Wikipedia로 학습된 CCNet을 통해 전체 문서에서 score가 0.65 이하인 문서를 삭제함)을 통해 전체의 48%문서만 남게 되며 가장 많은 데이터가 탈락됨을 알 수 있다.
- 이러한 과정을 통해 정제한 RefinedWeb데이터로 학습한 모델이 사람에 의해 엄선된 데이터나 기존의 웹데이터셋보다 우수하다는 것을 확인. (The Pile이 참고로 curated corpora임)
- 위와 같이 데이터셋의 우수성을 어떠한 모델에서 검증했는가를 보았을 때, 1B,3B등의 매개변수를 가진 GPT-3와 유사한 디코더 모델을 사용했는데 LLaMA와는 성능비교를 하지 않았다. 이유는 LLaMA의 가장 작은 모델도 2.5배의 (토큰 기준인지 명확히 쓰여있지 않음) 학습을 시켰기 때문이라고 일축되어있다.
- 본 논문은 Falcon의 모델이 아닌 데이터셋인 RefinedWeb의 필터링 과정과 성능을 중점에 두고 쓰여진것을 확인할 수 있었다.
'논문읽기' 카테고리의 다른 글
| 논문_REACT (Reasoning and Acting) (0) | 2023.11.27 |
|---|---|
| Rotary Position Embedding리뷰 (0) | 2023.11.25 |
| LoRA(LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGEMODELS ) 논문읽기 (4) | 2023.11.25 |
| [딥러닝 논문읽기] Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing (얼굴위조방지 관련 모델) (0) | 2023.01.05 |



