- QA나 Fever task(fact extraction and verification)에서 우수한 성능을 내기 위한 prompt 공법에 관한 논문.
- QA task를 수행하기 위해 단순히 GPT와 같은 LLM을 사용할때 단순히 질문만 던지는 것이 아니라 Reasoning, Acting을 거듭 거쳐 answer를 줄 것을 요구함으로서 더 높은 성능을 얻을 수 있다고 주장
- 예시 propmpt는 아래와 같음
instruction = """Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation, and Action can be three types:
(1) Search[entity], which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it will return some similar entities to search.
(2) Lookup[keyword], which returns the next sentence containing keyword in the current passage.
(3) Finish[answer], which returns the answer and finishes the task.
Here are some examples.
"""
- 논문에 따르면, acting-only (search만 계속 함), reasoning-only( LLM에서 질문의 답을 얻는 등)만 하는 식보다는 두개를 모두 요구하는 프롬프트를 통하여 시너지를 얻을 수 있다
- 주 실험은 PaLM model에서 이루어졌으며, 논문에서 “finetune”이라고 표현한 부분의 detail은 자세히 소개되어 있지 않으나 prompt를 통해 몇천단위로 연속 ReACT를 하여 정답을 추론하는 과정을 말하는 듯 함. 연속적인 step이 많을수록 성능이 좋았다고 한다. (아래참조)
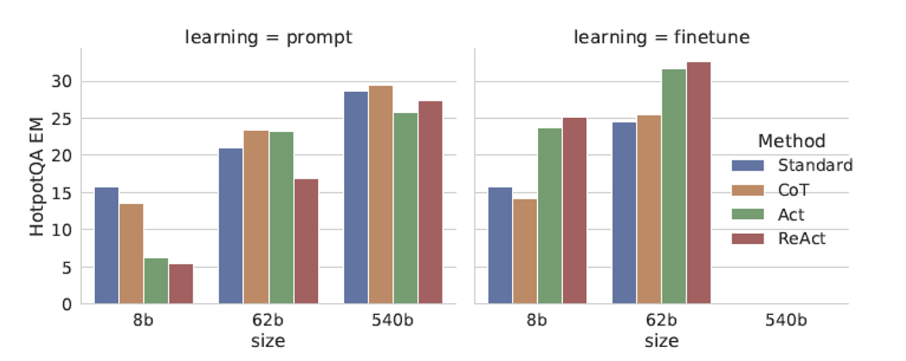
아래의 예시문은 논문 본문의 예시보다 더 차이가 잘 보여서 가져옴.

'논문읽기' 카테고리의 다른 글
| 논문 초록읽기 (딥러닝,LLM관련) (0) | 2023.11.26 |
|---|---|
| Rotary Position Embedding리뷰 (0) | 2023.11.25 |
| LoRA(LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGEMODELS ) 논문읽기 (4) | 2023.11.25 |
| [딥러닝 논문읽기] Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing (얼굴위조방지 관련 모델) (0) | 2023.01.05 |



